Suno AI の作り方 (技術者の観点から)
日本音響学会 学生・若手フォーラム Advent Calendar 2023 24日目
Suno AI とは、歌詞と曲のスタイル(と曲名)を指定するだけで、自動で歌詞入りの楽曲を作成してくれる生成 AI サービスです。
最近ではこのほかにも様々な音楽生成AIが発表されていますが、 Suno AI が特にバズっている要因はおそらく歌詞入力という他サービスではあまり無い UI と、 ボーカルが付加されることにより生成楽曲の面白さが格段に上がる点が大きいのではないでしょうか。
Suno AI 自体の使い方や詳細は多くのブログで紹介されているため特に取り上げる必要はないかと思いますが、 本記事では技術者の観点から Suno AI のようなシステムをどのようにすれば作れるか具体的に解説します。
個人的には Suno AI について、以下のような所見を持っています。
- Suno AI は現在公開されている技術の組み合わせで作ることは可能
- ただし、作成のハードルは学習データ集めや倫理的観点から高め
つまり以下の記事は、無限の財力を持った個人が Suno AI のようなものを個人的用途のみのために作りたいなと思ったときに役立つと思います。
Suno AI の仕様
Suno AI システムの入出力を簡潔にまとめると次の通りです。
- 入力: 1.歌詞、2.曲のスタイル、3.曲名
- 出力: ステレオ楽曲(48kHz)
入力は全てテキストです。シンプルですね。 これらの入力のうち、3.曲名が楽曲生成のために使用されているのかは不明です。
ざっくりと音楽生成 AI のトレンドを解説
ここ数年で数多くの音楽生成 AI が発表されていますが、おおまかにはほぼ全てのモデルが同じようなフレームワークを使っています。
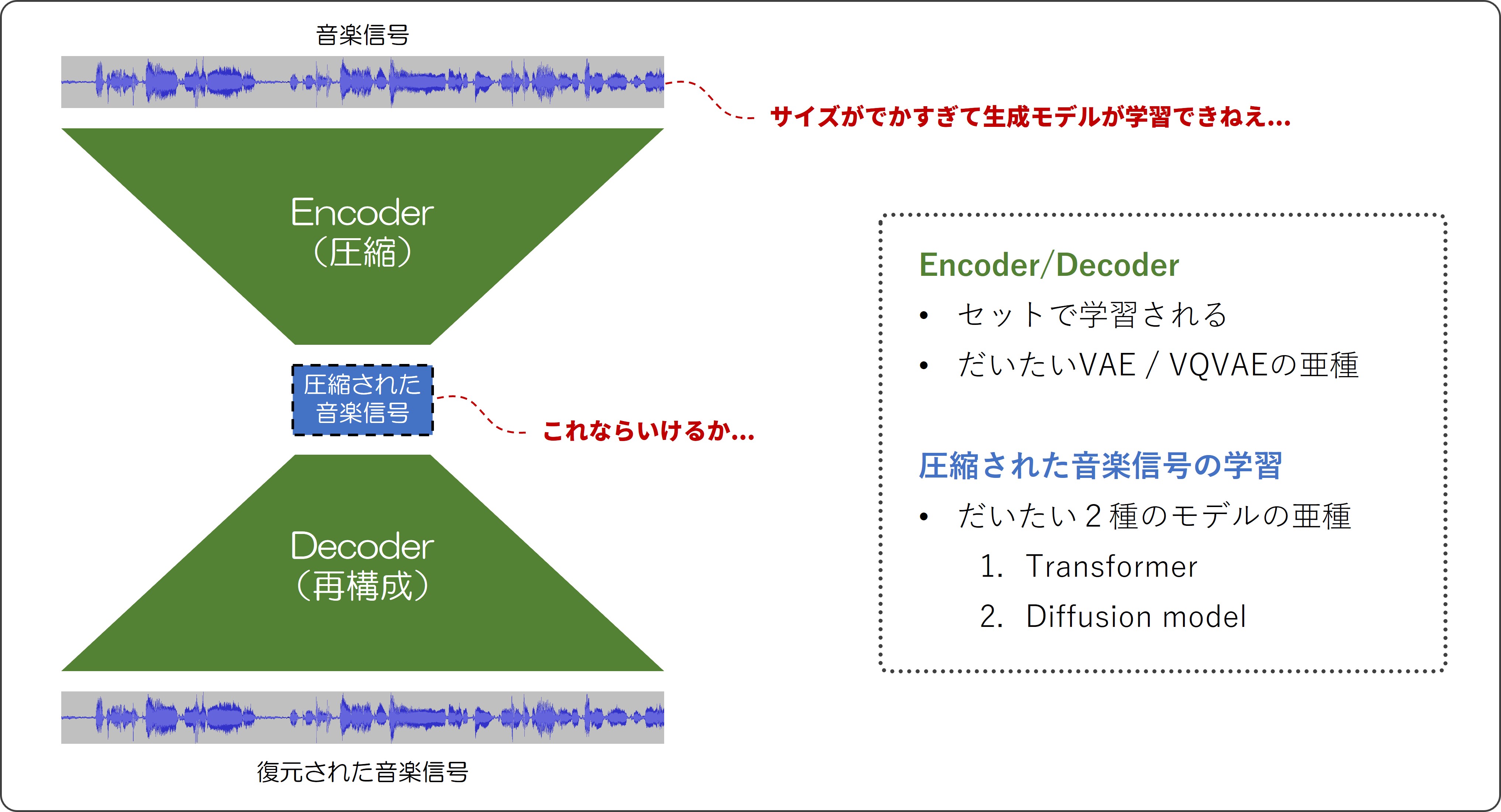
まず、生成モデルというものは生成したい対象のデータが小さければ小さいほどうまく学習できます。 しかし、音データ(特に音楽データ)は画像などと比べてサイズがかなり大きかったり信号自体が複雑だったりすることから、 同じような仕組みで学習しようとしてもあまりうまくいかないことが多いです。
そこで、現在の音楽生成 AI の枠組みとしては、生成モデルと圧縮モデルを組み合わせて使うものが一般的となっています。 具体的には、まず音楽を圧縮するためのモデルを学習して、音楽データを元のサイズより小さくできるようにします。 そして、この小さくなったサイズのデータを生成モデルで学習するというわけです。 データが小さくなっている分、生成モデルはよりうまく学習できるようになるし、圧縮モデルもうまく学習できているとすると、 生成モデルで生成された圧縮データから信号を再構成することで良い感じの音楽が作れることになります。
(ちなみに、画像データに関してもより高画質でリッチなものを生成するために、 現在では圧縮モデルを用いるフレームワークもよく使われています。Stable Diffusion などが有名ですね。)
具体的に Suno AI ではどんなモデルが使われているか?
コードなどは公開されていないため正直不明です。 そこで、ここでは同じような入出力を行えるシステムを作るという観点から考えてみましょう。
Suno AI で生成した楽曲をダウンロードしてスペクトルを観察してみます。
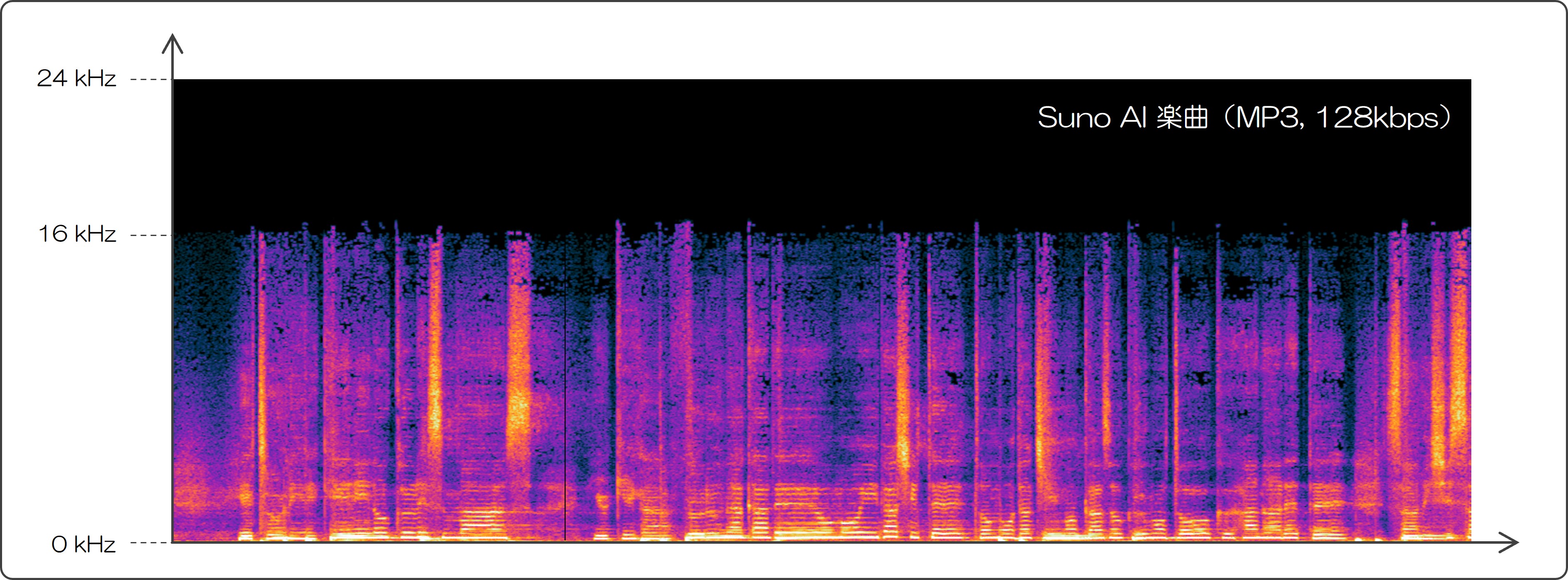
生成した楽曲は mp3 (48kHz sampling, 128kbps) フォーマットでダウンロードすることができます。 上記は信号のスペクトログラムを可視化したもので、おおよそ 16kHz より高い音は失われていることが分かります。
残念ながら 128kbps MP3 フォーマットにより失われる周波数帯域もちょうど 16kHz 以上であるため、 この劣化が音楽生成を行った時点で起きているのか判別することはできません。 しかし、開発者の立場として考えると音質良く生成された楽曲をわざわざ MP3 で提供するために音質劣化させるということは考えにくいような気もします。
このことから、もし生成の時点の音質が MP3 と同等である場合、内部的には 32 kHz サンプリングで処理されている可能性も高いかと思います。32 kHz サンプリングといえば思い出すのは、Meta が公開した音楽生成モデルである MusicGen とそれに用いられている学習済み圧縮モデルである EnCodec ですね。
MusicGen(生成モデル)
EnCodec(圧縮モデル)
実際、Suno は Bark という GPT(つまり比較的シンプルな Transformer)をベースとした汎用的な音の生成モデルを公開しており、圧縮モデルとして EnCodec を使用していることが記載されています。

これらのことから、Suno AI では MusicGen と同じような仕組みが使われている可能性がそれなりに高いかもしれません。
モデル学習の方法
さて、Suno AI が多くのサービスと異なるのは、歌詞を入力としてボーカル付きの楽曲を生成できる点です。 しかし実は、学習の際に歌詞とそれに対応した多くの楽曲データがあればある程度ボーカル付きの生成が行えるということは、 2019年に発表された OpenAI の Jukebox で示されていました。
Jukebox [2019] は MusicGen [2023] と同様の Transformer base のモデルとなっていますが、 当然ながら圧縮モデル・生成モデル双方の性能が圧倒的に向上しているわけなので、 現在のモデルを使えば当時よりも高いクオリティで音楽を生成できることは想像に難くないかと思います。
どうやって学習データを作る?
結局、学習データがないと生成モデルを学習することができません。 ここで、Suno AI 的なものを作るために必要な学習データをまとめてみましょう。
- 音楽信号
- 上記音楽信号に対応する歌詞(テキスト)
- 音楽のスタイル情報(テキスト)
ちなみに、Jukebox では 120 万曲程度の音楽トラックとそれに対応するジャンル・アーティスト・歌詞という情報をウェブクローリングと LyricWiki というサイトを通して集めたようです。

(Jukebox より)
Suno AI では多言語(英語・日本語 etc…)に対応していることから、 学習にさらに多くのデータを使っていることは間違いなさそうです。 音楽信号自体は、例えば Youtube やその他のサービスからウェブクローリングで集められるとしても、 ここで問題となるのは歌詞や音楽スタイルといったメタ情報をどのように集めるかということです。
音楽のスタイル情報(テキスト)
音楽のスタイル情報とは、「テンポの速い80年代スタイルのクラブミュージック」といった 音楽のスタイルを具体的に描写したテキスト情報となります。 これらはウェブからクローリングする方法ももちろんありますが、 多くの音楽を集める場合、そういった情報が付加されていないことも少なくありません。 あまりにスタイル情報が少ないと生成モデルの学習に悪影響を与えてしまうため好ましくありません。
そこで、そういったテキスト情報を得るために最近では「テキストと音楽を対応させて学習されたモデル」 を活用するテクニックがよく使われたりします。 詳細は割愛しますが簡単にいうと、テキストと同じ情報が音楽信号のみから取得できるため、データ集めの際に別にスタイル情報が付いてなくても問題ないということです。これによってデータ集めのハードルがむっちゃ下がりますよね。
具体的にこのテクニックを使った音楽生成モデルとして例えば MusicLDM というものがあり、テキスト情報抽出には CLAP というモデルが使われています。
MusicLDM → 音楽生成モデルの一例
CLAP → 音楽信号自体からテキスト情報を取り出せるモデル
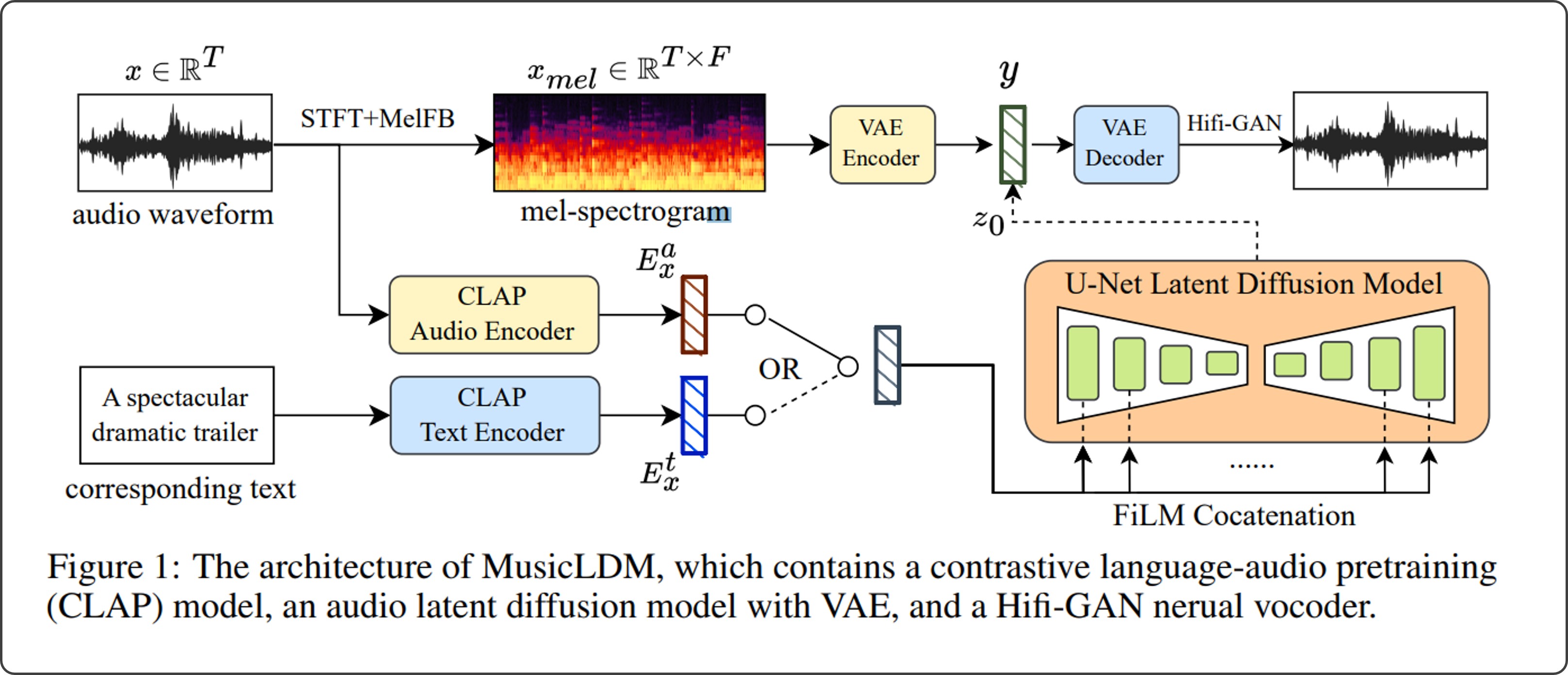
(MusicLDM 論文 より)
音楽の歌詞情報(テキスト)
音楽の歌詞情報は収集するのがより難しそうですね。 実際、無作為に音楽データを収集すると歌詞データが付いていないことも多いかもしれません。
実際どのように解決しているかは不明ですが、もし自分が実装するならば…
楽曲からボーカルを抽出する学習済みモデルと、歌詞認識する学習済みモデルを使います。
結局、音楽信号に対応する歌詞情報をゲットできればいいということなので、
これを現在の技術を使って自動化しようということです。
人の話している内容を認識する音声認識と同様に、歌っている内容を認識する歌詞認識の技術もいろいろと研究されており、 現在ではまあまあな精度で歌詞を書き起こせるんじゃないでしょうか。 流石に伴奏が混ざったままの音から歌詞を認識するのは難しそうなので、この前段階としてボーカル抽出を使うと良さそうです。 例えば、現在最も性能の良いボーカル抽出技術の一つである HT Demucs のデモを以下から聴くことができますが、 これだけ抽出できていれば歌詞認識もやりやすいだろうなと実感することができると思います。
ここで気になるのが、現在最高性能の技術を使ってもある程度 エラー(認識誤り) が含まれてしまうという点ではないでしょうか? 例えば、「今宵はほら二人で1000%LOVE」が「今宵はオランダにて先輩全裸」と認識されてしまったりするわけです。
ただ、個人的にこの認識誤りは問題ないんじゃないかと予想しています。 生成モデルを学習する際のテクニックとして、完全に正しい正解データではなく少しノイズ(間違い) の乗ったデータを使った方がモデルが安定的に学習出来てうまくいくといったテクニックがよく報告されているので、 それを鑑みるに歌詞の認識が 80~90% くらいしか出来ていなかったとしても、 生成モデルの学習はわりとうまくいくんじゃないかと思ったりしています。(実際にやってみないと分からないですが。)
まとめ
データを集めたうえでこんな感じの枠組みをで学習を行えば Suno AI っぽいものが作れると思います。
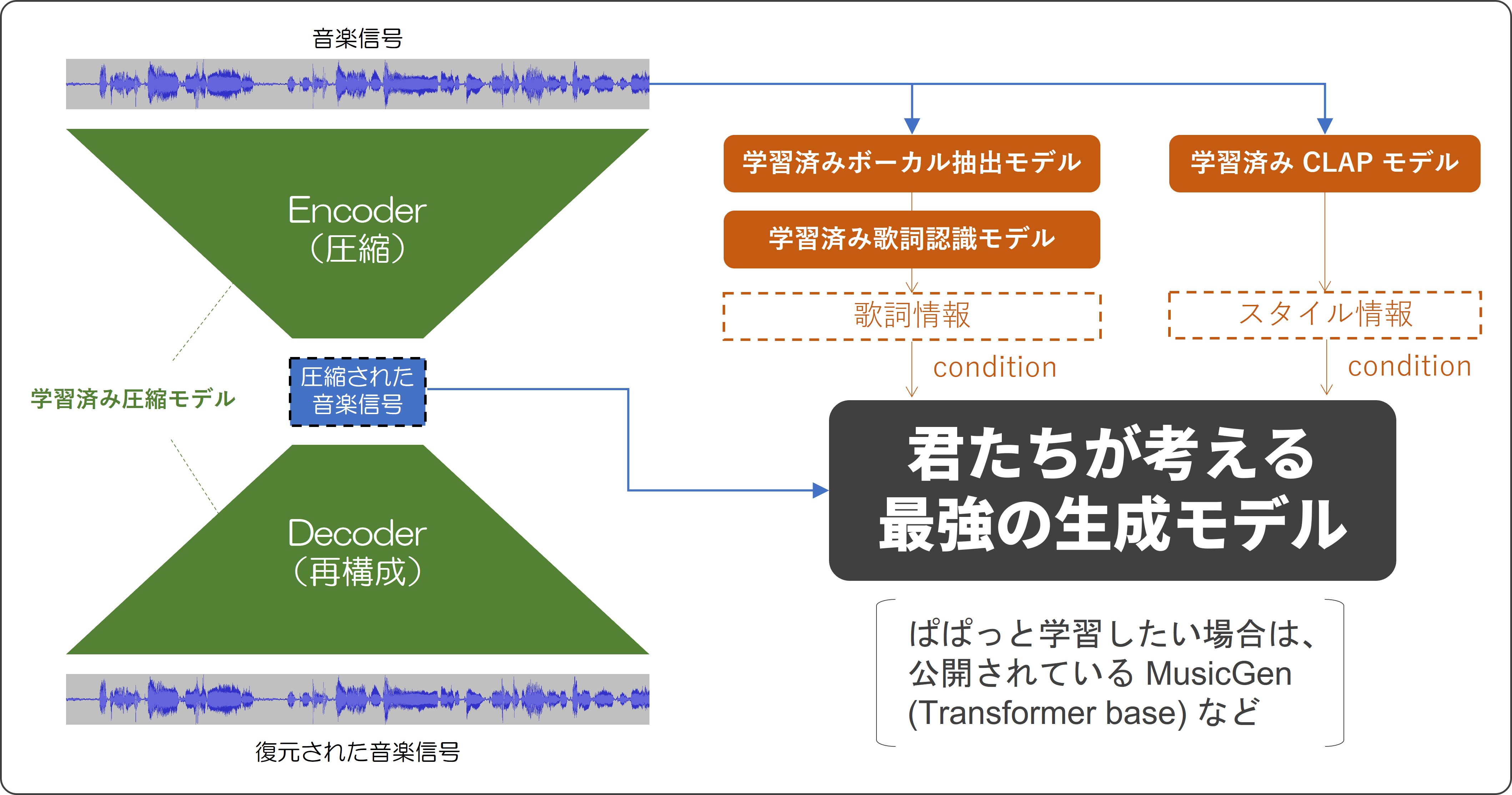
おまけ:技術者の立場から Suno AI で遊んでみる
パクリ音楽対策
Suno AI では現実に存在する丸パクリの歌詞やアーティスト名を入力しようとすると、以下のようなエラーが出て生成を行えません。 この辺の検出の仕組みも気になるところです。いろいろ工夫して実在する有名曲にそっくりなものを生成しようとしましたが、なかなか難しかったです。
音楽生成あるある:ユーザが指定していないところはどう生成される?
Suno AI は歌詞を入力して生成を走らせると、その歌詞の長さにおおよそ合った音楽と 1:20 程度の長さの音楽の2パターンがデフォルトでは生成されるらしい。音楽生成モデルさん的には、むっちゃ短い歌詞を入力されると長さが足りない部分に関しては頑張って自分でボーカルっぽいものを生成しようとせざるを得ないはず。
Title: ロバートソン.
なんとなくスピッツっぽいかもしれない。
(画像は宇宙カレー?)
歌詞を指定いない部分では、声っぽく聴こえるけど言語としては成り立っていない音が生成されるようだ。これは生成モデルあるある。 自動生成画像もどちらかというと歌詞を使って生成しているんだろうか。
音楽生成あるある:学習データに入って無さそうな歌詞はムズイ?
生成 AI は多くのデータから学習ことによって、生成時にある程度無茶振りされてもわりと頑張って生成してくれたりします。 それでも、「絶対に学習データに入ってないよね?」と思われるような単語を入力したらむちゃくちゃになったりするんでしょうか?
Title: Very sad song.
複雑骨折について歌った女性歌手がいなさすぎて、完全にボーカルを生成するのに失敗。
やけになって「最高だ~!」とか歌いだしてないか?
Title: Very sad song.
実は学習のときに、あまり漢字が取り入れられてないだけで、ひらがな入力すれば急に流暢になったりする。
(朗読は怖いよ..)
Title: Too much pain.
せつない雰囲気。
東海道中膝栗毛もまあまあ歌える場合が多くてすごいなと思った。 なんか日本語で変な歌詞を歌わせようとするとボーカロイドっぽい歌声になる確率が高い。 日本語楽曲データ内でのボーカロイド割合が高いんだろうか。
Title: Movie star.
「なにか?」ではないが
知り合いが言ってたけど、Gangsta Rap にすれば大体どんな歌詞でもいける説。
Title: Very sad song.
骨折シリーズで好きだったやつ。サディスティック・ミカ・バンドみたい。