お絵描きAIの中では何をしているか?
本記事は、一般的なお絵描きAIの仕組みを非エンジニア向けに説明したものです。 これから様々な生成系AIが出てくる中で、技術的な仕組みを直観的にでも理解しておこう、 といったことを目的としています。 より詳しい方は、Stable Diffusion の元となっている以下の論文などをご参照ください。
(arxiv link) High-Resolution Image Synthesis with Latent Diffusion Models
データとしての画像
まずは画像をコンピュータが扱うデータとして見てみましょう。
画像は pixel の集まりです。1000 x 1000 サイズの画像は 100万 pixel で構成されています。 世の中の多くの画像では、この 1 pixel が 8 bits (つまり 0–255 の数値) で保存されているため、 どのような画像でも以下のような数値の集まりとなっています。
 画像は pixel (数値) の集まり
画像は pixel (数値) の集まり
ちなみに上記は白黒画像の例ですが、 普段よく目にするカラー画像では 1 pixel に3種類の 8 bits 情報を持っているため、データ量が3倍となります。
人が「絵画」として認識するもの
1000x1000 (100万 pixel) の画像には、何通りの絵が含まれているでしょうか? 1 pixel に 256 通りのパターンがあるわけですから、100万 pixel の場合はシンプルに以下の個数の絵が含まれていることが分かります。
$$ N_{all} = 256^{1000000} $$
むっちゃ多いです。
ところで、難しいAIを使わなくてもこの画像群から何らかの画像を生成する「お絵描きAI」を実現することができます。
100 万 pixel それぞれに対して、ランダムに 0–255 の数字を選べばよいだけですね。
 学習していないAIで 10 個の絵画を生成してみた例
学習していないAIで 10 個の絵画を生成してみた例
しかし、このようにして生成された画像はほとんどの人が絵画ではないノイズだと認識すると思います。 動物のイラスト、車の写真、上で計算した全画像群の中にはそういったものが全て含まれているはずなのに、なぜ"偶然にも"それらは生成されないのでしょうか?
画像の"分布"
ランダムに生成した画像が人にとって意味のないものとなる理由は、 「人が絵画と認識する画像(または人がお絵描きAIに生成してほしい画像)は、全画像群の中では"ごく一部"だから」です。 この全画像内での(人が所望する)データの偏りを"分布"といいます。
**「ランダムな画像」と聞いて抽象画などを想像する人もいるかもしれませんが、 それらの絵画も筆のストロークなどを含んでいる時点で非常に偏った分布を持っています。
画像の分布を可視化しよう
画像の分布を可視化してみて、より具体的なイメージを掴みましょう。 100万 pixel の分布はさすがに難しいので、ここでは 1x2 (つまり 2 pixel!) の画像を考えます。 2 pixel の場合では、たった 256 x 256 のデータ空間の中に全画像が含まれていることが分かりますね。
 2pixel 画像の例
2pixel 画像の例
ここで 300 人のアーティストを招き「2 pixel 絵画コンテスト」を開催した結果、 以下のような作品が集まったとします。 2 pixel なので 2 次元空間上に可視化することができました。
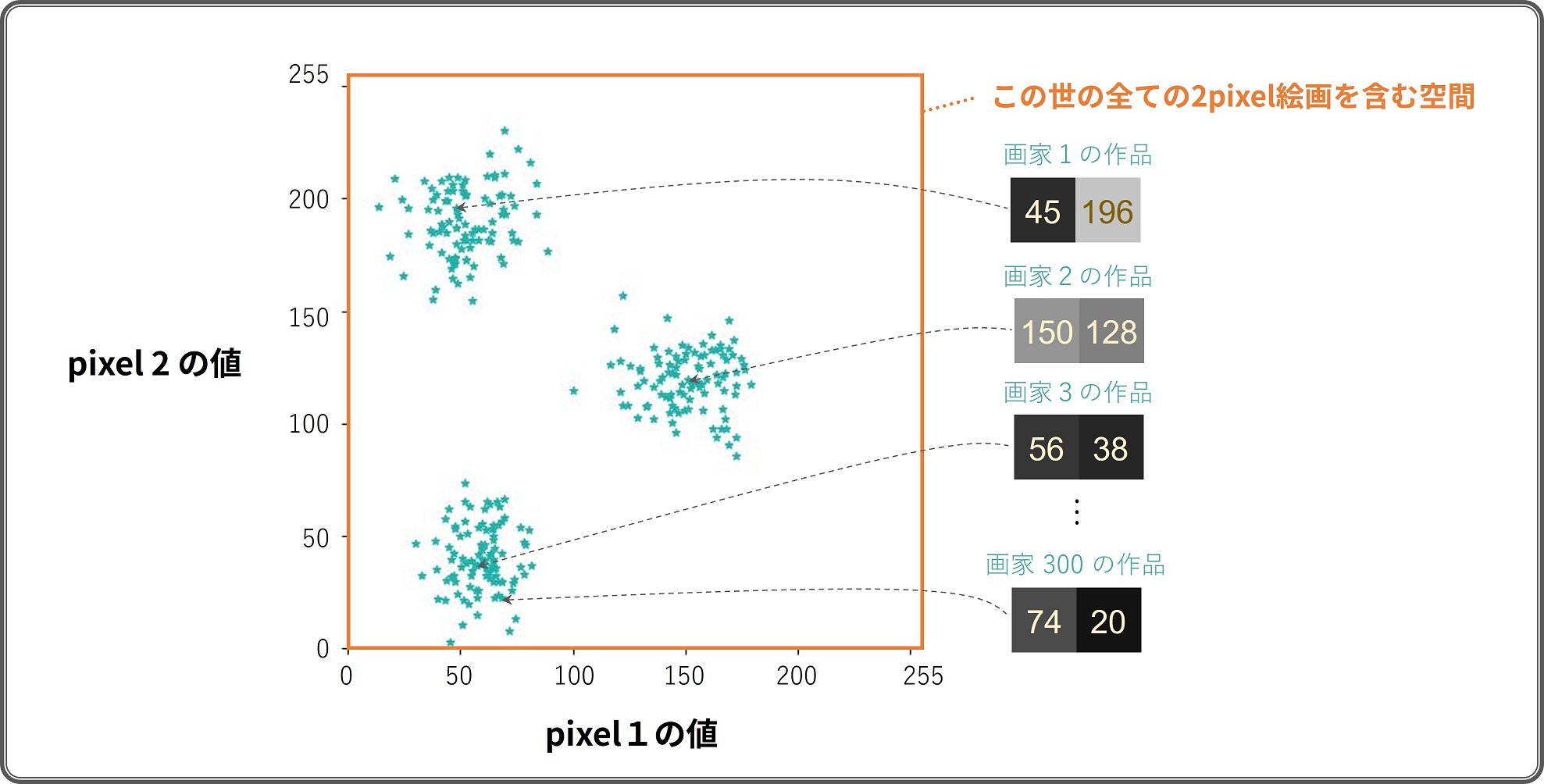 300枚の 2pixel 絵画を座標上に可視化したもの
300枚の 2pixel 絵画を座標上に可視化したもの
各アーティストの作品は違った pixel 値を持っているものの、 全体として明らかに"傾向"があるように見えます。 具体的には、全作品が空間上の3つの場所に集まっている気がします。 これが先に述べた絵画画像の"分布"ということになります。
お絵描きAIの学習
さて、ご存じの通りお絵描きAIは多くの作品によって学習されています。 そしてこの学習の本質は、先述した「絵画画像の分布」を学習することなのです。
より具体的に、おおまかなお絵描きのステップは以下のとおりです。
- 学習:数学的に絵画画像の分布を推定する
- 生成:推定された分布から存在確率の高い画像を生成
「学習」でより正確に分布を捉えられているほど、 「生成」においてよりそれっぽい画像を得ることができます。
この分布の学習のために、近年猛威を奮っているのがディープラーニングであり、 Stable Diffusion の元となっている “Diffusion model” や “Transformer” といったものもいわば「分布学習AI」の一種です。
** 分布からのデータ生成は、専門的には「サンプリング」と呼ばれることが多いです。
学習と生成をやってみよう
では実際に、「2 pixel 絵画コンテスト」の作品を使ってお絵描きAIを学習してみましょう。
今回の学習では「混合ガウス分布(a.k.a. GMM)1」という"AI"を使いました。 GMM は流行りのディープラーニングではありませんが、 様々な形状の分布の学習とデータ生成が簡易に行えることから多くの分野で利用されている、 非常に有用な手法の一つです。
300 枚の 2 pixel 絵画から AI を学習した結果以下のような"分布"が得られました。 学習された結果、色の濃い部分(紫色の部分)に人間による絵画が存在している確率が高い と AI が判断できるようになったわけです。
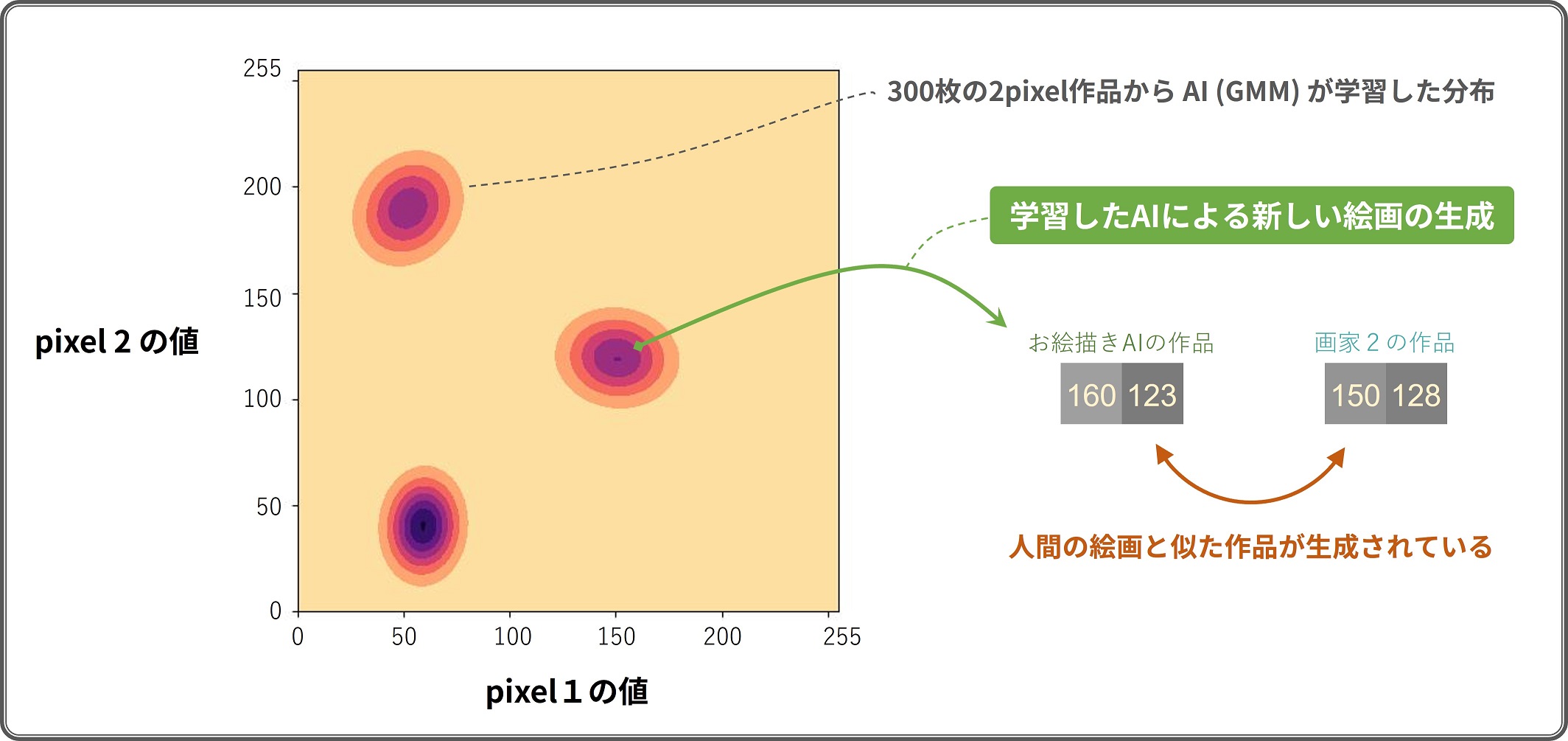 300 枚の 2pixel 絵画から AI が学習した分布と、新しい絵画の生成
300 枚の 2pixel 絵画から AI が学習した分布と、新しい絵画の生成
新しい絵画の生成は、学習された分布上の確率が高いところから適当に画像を選ぶことで行われます。 このように絵画を生成した結果、学習に使った作品と「似ている2」けれども全く新しい絵画が生成されるというわけです。
入力した絵画と「画風が同じ」絵画の生成
お絵描きAIの応用の一つとして「あるアーティストの作品を入力として、それに似た作品を生成する」 というものがあるかもしれません。 この技術はどのようにして実現されるでしょうか?
AI による絵画の概念の獲得には多くの学習データが必要であり、 1枚の入力画像からそのアーティストの「画風」などを学習することはできません。 そこで、事前に多くのデータにより学習された AI を利用することを考えます。
先述した 300 枚の 2pixel 絵画から学習された分布の 1 pixel 目が「画風」、2 pixel 目が「風景」を表していたと仮定しましょう3。
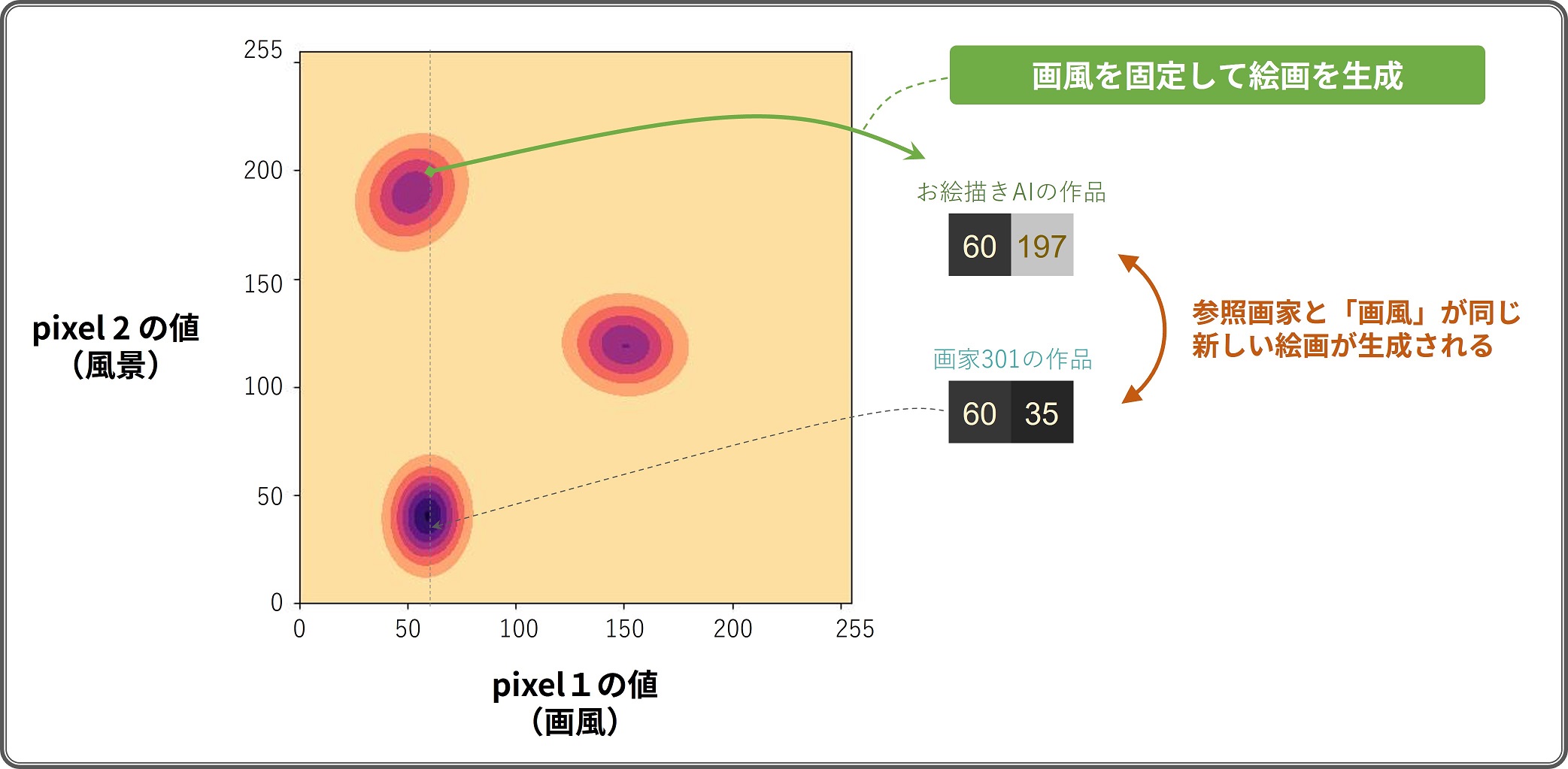 入力した作品の「画風」を模倣した生成
入力した作品の「画風」を模倣した生成
このとき、学習には用いられていない 301 人目の画家の作品からうまいこと「画風」の数値が取り出せたとします。 そうすると「画風」の数値は固定したまま、事前に学習された分布 (AI) から確率の高い、 かつ「風景」の異なる絵画を生成することができます。 このように生成された絵画は、入力した作品と画風は同じだが全く異なるものを描いた作品となっていることになります。
お絵描きAIはこんな感じで新しい絵画を生成しています。しらんけど。
-
正確には GMM は分布自体の名前であり、この分布の形状を学習するための手法がいくつか存在し、 今回はそのうちの一つを使っている形となります。 ↩︎
-
「似ている」絵画の基準は曖昧で具体的に決められるものではありません。 2pixelの例では、画素値が直接的に近い形になりますが、高解像度の絵画の学習においては、 この概念も AI の中で抽象的に学習されていくことになります。 ↩︎
-
ディープラーニングにおける絵画学習において「画風」や「アーティスト」、 「顔の向き」などの人間に分かりやすい概念を学習したい場合は、 それらが明示的に学習されるように難しい工夫をいっぱい入れます。 一般的に、とても複雑です。 ↩︎